안녕하세요
삼성SDS Brightics 서포터즈 3기, 비전공생입니다!

지난주에는 불균형 데이터의 밸런스를 맞추기 위한 작업을 오버샘플링(SMOTE) 기법을 활용하여 진행하였는데요.
이번에는 그렇게 균형을 맞춘 데이터를 기반으로 머신러닝을 학습시키고 Test데이터에 적용하여 평가를 해보려고 합니다!
1. Decision Tree Classification Train
우선 SMOTE를 통해 균형을 맞춘 Train 데이터를 활용하여,
의사결정나무 분류모델로 학습시켜보겠습니다.

해당 모델 블럭을 선택한 후, Feature Columns와 Label Column을 설정해준 후 실행해보았습니다.
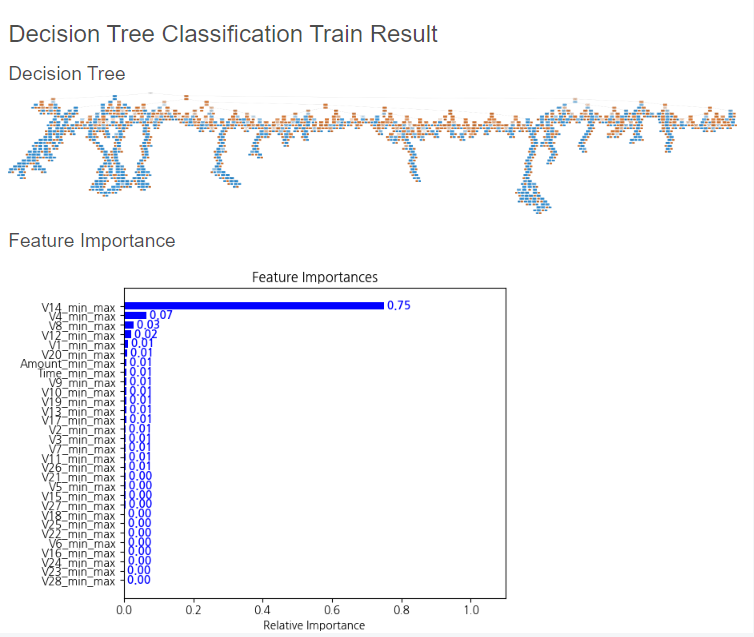
그랬더니, 위와 같은 결과를 확인할 수 있었습니다.
2. Test 데이터 정규화
그럼 다음으로는, 처음에 따로 분리해둔 Test 데이터를
Train 데이터와 동일하게 정규화해보도록 하겠습니다.
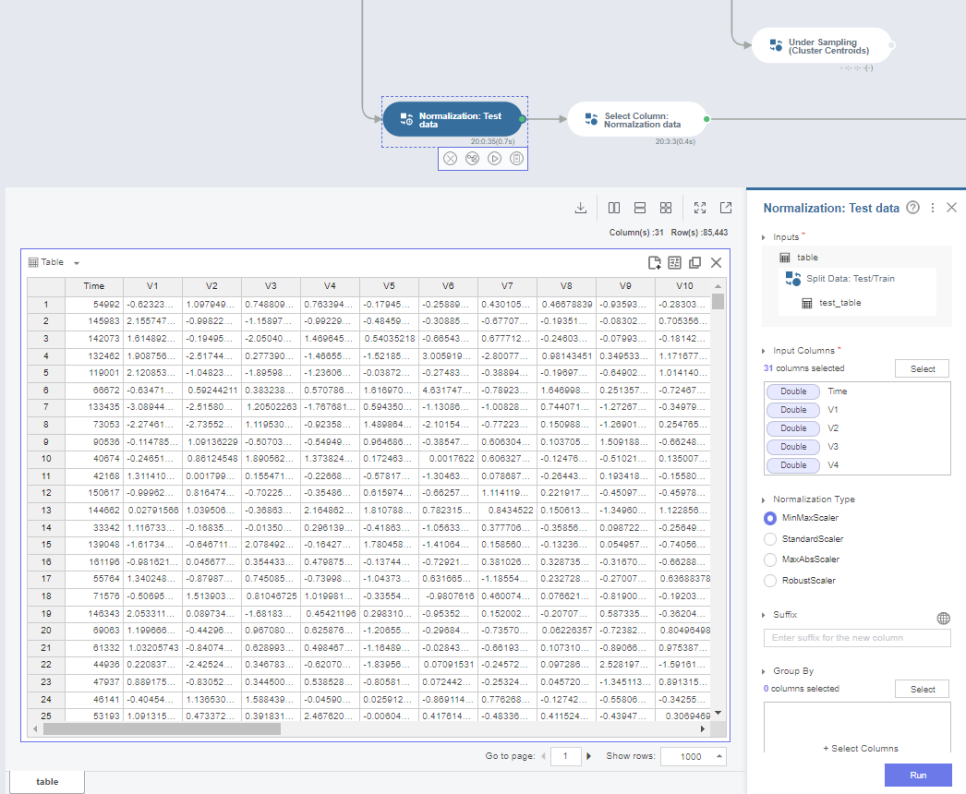
아래의 결과값을 비교해보면, 0~1 사이의 값으로 정규화가 잘 진행된 것을 확인할 수 있습니다.
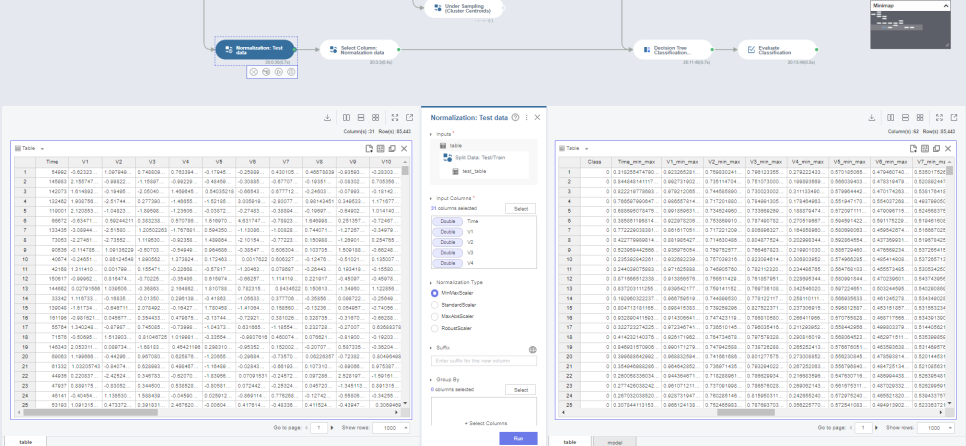
지난번 Train 데이터 정규화를 진행해주었던 것처럼,
Test 데이터 정규화에서도 정규화가 완료된 컬럼만 따로 뽑아주는 작업을 진행하였습니다.

3. 학습된 머신러닝 모델에 Test 데이터 적용
이제 좀 아까 위에서 만들어둔 Desicion Tree Classification 모델을 활용하여
Test 데이터를 예측해보도록 하겠습니다.

위의 흐름을 통해 진행중인 것으로 이해해주시면 될 것 같습니다!

Test 데이터를 불러와 학습된 모델을 기반으로 예측을 진행하였습니다!
4. 예측 모델 평가
오늘의 마지막 작업으로, 모델 평가를 진행해보겠습니다.

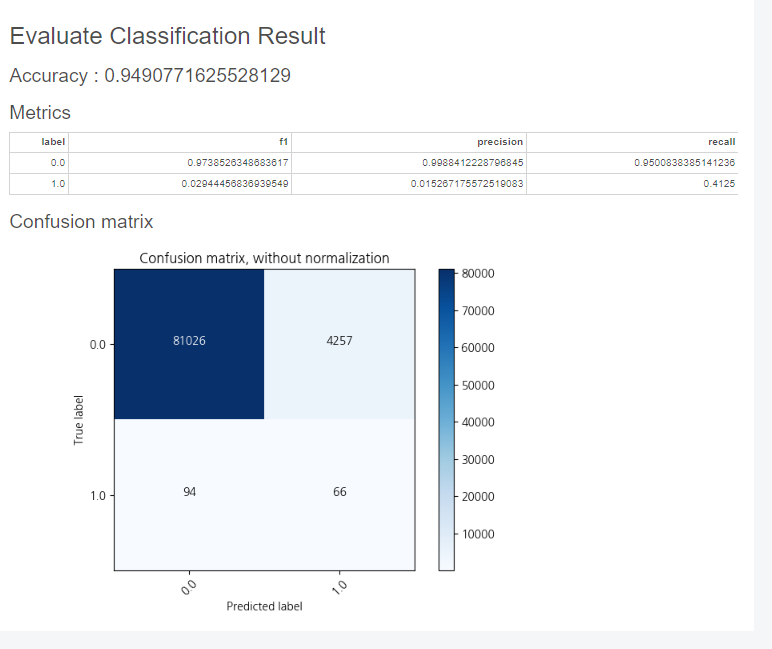
Evaluate Classification 함수를 활용해서 평가를 진행하였습니다!
결과는 아래와 같은데요!
Accracy 94%, label 1을 기준으로 Precision 0%, Recall 41%로 결과값이 처참한 것을 보실 수 있습니다..
이를 어떻게 개선할 수 있을지, 무엇이 문제였을지 더 고민해보고
다음주에는 여러가지 방식으로 모델링을 진행해보며 성능 비교를 해보도록 하겠습니다

추가로, 지금은 불균형 데이터 처리 단계에서 오버샘플링만 적용을 해보았는데,
다음에는 언더샘플링도 진행해 동일한 모델로 더 나은 결과를 확인할 수 있을지도 비교해볼 예정입니다!
그럼 오늘도 긴 글 읽어주셔서 감사드리고,
다음주에 다시 찾아뵙겠습니다!
*본 포스팅은 삼성SDS Brightics 서포터즈 3기 활동의 일환으로 작성하였습니다.
'삼성SDS Brightics > 브라이틱스 서포터즈' 카테고리의 다른 글
| [삼성SDS Brightics] FDS 이상거래 탐지 #6편- 랜덤 포레스트 하이퍼파라미터 튜닝(Random Forest, Hyperparameter) (1) | 2022.11.08 |
|---|---|
| [삼성SDS Brightics] FDS 이상거래 탐지 #5편- 머신러닝 모델링 (Random Forest, XGB, AdaBoost) (0) | 2022.11.01 |
| [삼성SDS Brightics] FDS 이상거래 탐지 #3편- 불균형 데이터 처리 (언더샘플링, 오버샘플링, SMOTE 활용) (0) | 2022.10.19 |
| [삼성SDS Brightics] FDS 신용카드 이상거래 탐지 #2편 (0) | 2022.10.12 |
| [삼성SDS Brightics] FDS 신용카드 이상거래 탐지 #1편 (0) | 2022.10.05 |