안녕하세요
삼성SDS Brightics 서포터즈 3기, 비전공생입니다!

지난 주에는 Decision Tree Classification 모델을 통해 학습을 진행해보았는데요.
이상거래인 label 1을 기준으로 보았을 때, Precision 1%, Recall 41%로 안좋은 결과를 보였습니다.
이번에는 Random Forest, XGB, AdaBoost 분류 모델 3가지를 모두 진행해보고,
성능을 비교해보는 시간을 가져보려고 합니다!
그 전에, 제가 지난 주에 Test 데이터에 정규화를 적용할 때
Train과 동일한 모델로 적용하는 것을 놓쳤기 때문에,
그 부분을 먼저 수정하고 진행하도록 하겠습니다.
0. Noramalization Model
Train Set에서 진행한 정규화를 기반으로, 모델을 선택해줍니다.
아래의 모습처럼 화살표로 이어주면 되겠죠!

테이블에는 Test 데이터가, 모델에는 Train 데이터를 정규화했던 모델이
아래의 모습처럼 잘 들어갔다면, 완료입니다!

오늘 비교해볼 3가지 모델링의 흐름도를 먼저 넣어보았습니다.
Random Forest, XGB, AdaBoost 순으로 학습을 진행해보겠습니다!
1. Random Forest Classification
첫번째로, 랜덤 포레스트 분류 모델로 Train 데이터를 학습시켜보겠습니다.
지난 주 오버샘플링을 진행했던 Train 데이터를 table로 선택한 후 학습을 진행했습니다.

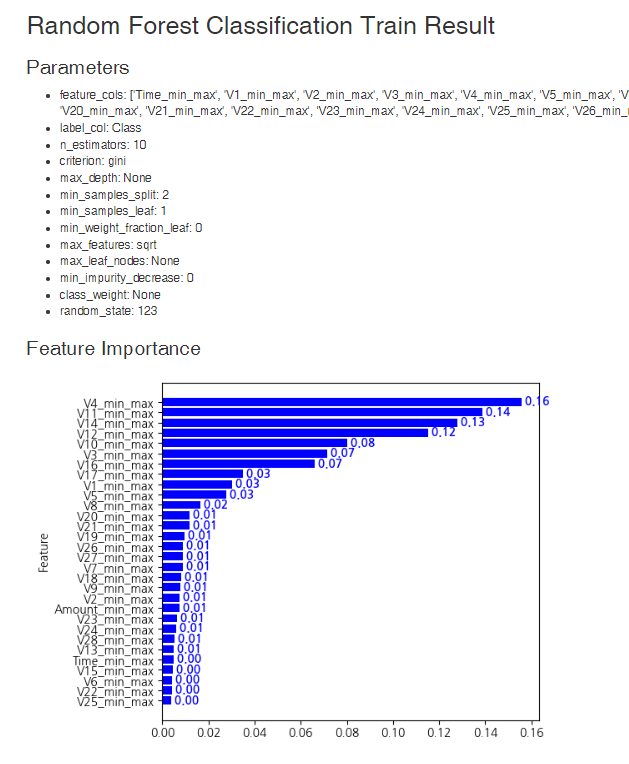
랜덤 포레스트 학습 결과값입니다.
영향력이 높은 변수들을 확인할 수 있는데요!
V4, V11, V14가 상위권에 포함되어 있네요.
학습된 모델을 기반으로, Test 데이터에 적용해보겠습니다!
앞에서 Train 데이터와 동일한 모델로 정규화를 진행한 Test 데이터를 테이블로 선택하고,
모델은 방금 전 학습시킨 Random Forest Classficaiton Train을 선택해줍니다.

Evaluate Classificaiton 함수를 통해 평가 지표를 확인해보겠습니다.
Accuracy 99%, f1 83%, Precision 86%, Recall 81%의 결과가 나왔습니다!
지난 주 트리 모델 성능과 비교하면 정말 많이 개선된 것 같습니다 :)
불균형 데이터에서는 f1 지표가 중요한 것으로 알고있는데요.
Recall이 올라갈수록, Precision이 내려갈 수 있기 때문에
f1이 그 둘의 밸런스(?)를 설명한다고 볼 수 있을 것 같습니다.
Recall 혹은 Precsion이 0에 수렴할수록, f1도 0에 수렴하게 되는 구조입니다.


2. XGB Classification
다음으로는, XGB 분류 모델을 통해 Train 데이터를 학습시켜보겠습니다.
마찬가지로 정규화된 Train 데이터를 table로 선택한 후 학습을 진행합니다.
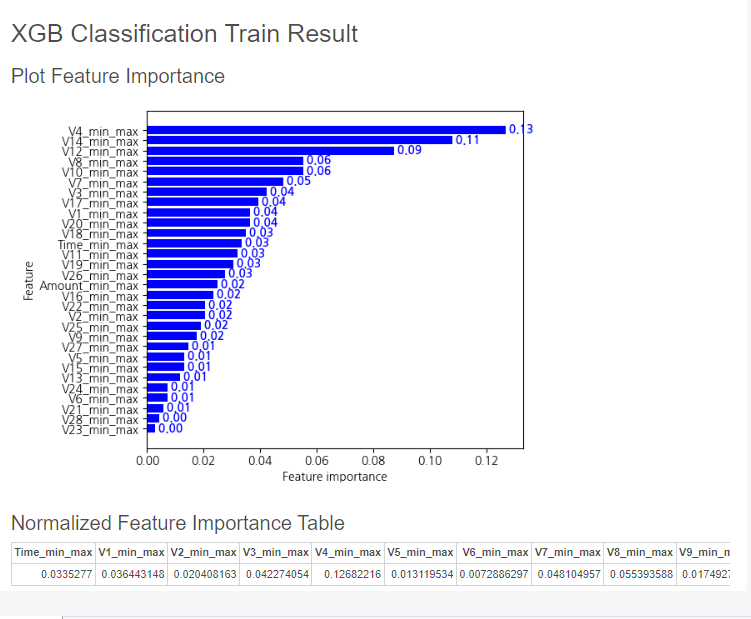
중요도가 높은 Feature들을 아래와 같이 확인할 수 있습니다.
위와 동일하게 V4, V14가 중요도가 높게 나오네요!
마찬가지로 이번엔 Test 데이터에 조금 전 학습시킨 XGB 분류 모델을 적용해보겠습니다.
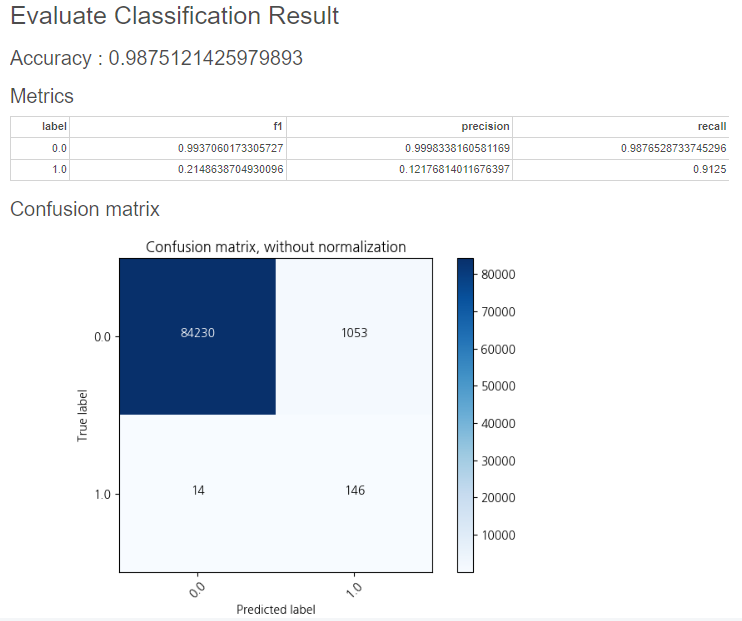
그 결과를 평가 지표로 확인해보겠습니다.
이번엔 Accuracy 98%, f1 21%, Precision 12%, Recall 91%의 결과가 나왔습니다!
랜덤 포레스트에 비해 Recall(재현율)은 90%대로 올라갔지만,
위에서 말씀드린 것처럼, Precision은 급격히 낮아졌습니다.
그래서 f1값을 보시면, 21%로 낮아진 것도 확인할 수 있습니다.

3. AdaBoost Classification
마지막으로, AdaBoost 분류 모델을 통해 Train 데이터를 학습시켜보겠습니다.
위 2 모델과 동일하게 정규화된 Train 데이터셋을 선택해 진행합니다.
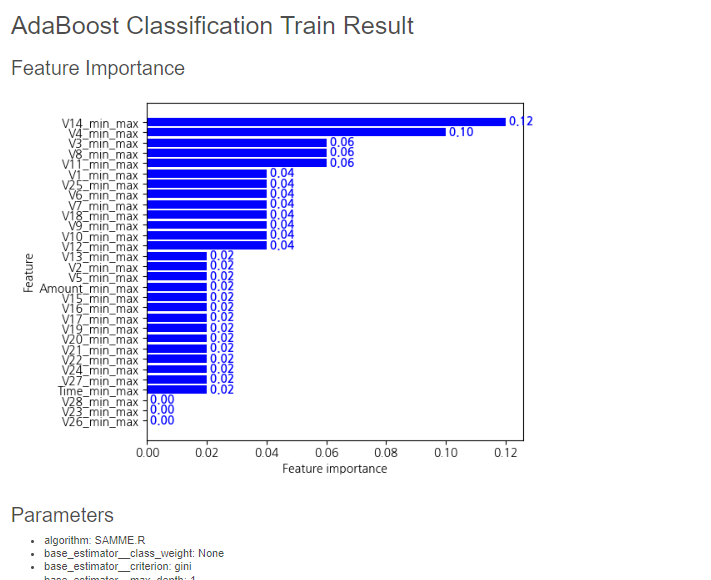
이번에도 중요한 Feature 상위권에 V14, V4가 포함되어 있네요.
마찬가지로 학습시킨 AdaBoost 모델을 Test 데이터에 적용하였습니다.

그 결과를 평가지표로 확인해보겠습니다.
이번에는 Accuracy 98%, f1 14%, Precision 7%, Recall 90%의 결과로,
마찬가지로 Recall(재현율)은 90%대를 유지하고 있지만, XGB보다도 Precision(정밀도)가 낮아졌고
그에 따라 f1도 더 낮아진 것을 확인할 수 있습니다.


4. 모델 성능 비교
이번 주에는 3가지 모델로 Train, Test를 진행해보았는데요.
그럼 간단히 3가지 모델의 평가 지표를 비교해보도록 하겠습니다.
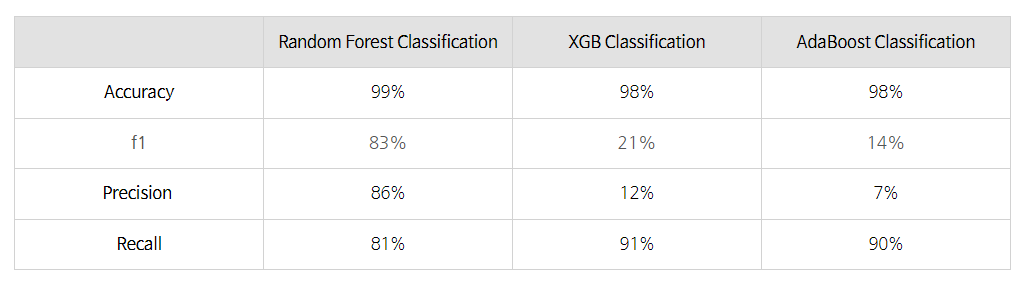
이렇게 정리가 되었는데, 랜덤포레스트는 4가지 지표 모두 80% 이상으로 안정적인 한편,
XGB와 AdaBoost는 Recall은 90%로 더 높지만, Precision이 너무 낮고, 이에 따라 f1도 낮은 결과를 얻었습니다.
따라서 저는 랜덤포레스트 모델로 선정을 하고, 거기서 어떻게 더 성능을 높일 수 있을지,
그리고 추가로 불균형 데이터 처리 기법을 다르게 하였을 때의 결과값 비교를 진행해서
마지막 정리를 해보도록 하겠습니다!
***
그리고 추가로!
브라이틱스 서포터즈 3기의 활동으로,
팀원들과 함께 열심히 촬영하고 편집한 영상이 업로드가 되어서,
홍보 차 내용을 공유드립니다.
https://www.youtube.com/watch?v=DvC7OUwfLSo&list=PLc50BLDT6Bv7-G5UO5Y4zBgJr9488coa1&index=3
많이 민망 머쓱했찌만, 팀원 모두가 열심히 연기에 참여하였답니다!
재밌게 시청해주시고, 좋아요와 댓글까지 부탁드려요~!
그럼 오늘도 긴 글 읽어주셔서 감사드리고,
다음주에 다시 찾아뵙겠습니다!
*본 포스팅은 삼성SDS Brightics 서포터즈 3기 활동의 일환으로 작성하였습니다.